Revocation at Device Scale: Why CRL and OCSP Fail, and What Replaces Them
Enterprise revocation assumes connected endpoints and responsive relying parties. At device scale, OCSP becomes a single point of failure and CRLs grow to hundreds of megabytes. The honest view of what works: short-lived LDevIDs, gateway enforcement, RFC 9773 ARI, and what remains unsolved.
Revocation is where the gap between enterprise and IoT PKI becomes undeniable. The enterprise model — OCSP responders, CRL distribution points, relying parties that check — works because enterprise endpoints are connected, relying parties are online, and the revocation decision propagates through infrastructure designed to carry it. None of these assumptions holds at device scale.
PKI Health Radar
Drag the sliders to assess your current posture — scores update instantly.
The honest position: revocation at device scale is partially an unsolved problem. The working answers are short-lived credentials (where the lifetime is itself the revocation mechanism), gateway-enforced revocation (where the device trusts a gateway to decide), and renewal pressure via RFC 9773 ARI (where the CA pushes clients to rotate early). What doesn't work is pretending OCSP extends to devices.
This matters for unified PKI because the revocation model is one of the five axes of divergence between enterprise and IoT operations. A platform that exposes the same revocation mechanism for both is a platform that gets one of them wrong.
Why enterprise revocation works
The enterprise model rests on OCSP (RFC 6960) with stapling (RFC 6066 §8) and CRLs (RFC 5280) as the fallback.
OCSP stapling removes the performance and privacy problems of plain OCSP by having the TLS server pre-fetch a signed OCSP response and attach it to the TLS handshake. The relying party gets revocation status without contacting the OCSP responder. This works because:
- The TLS server is always online (it's serving TLS).
- The OCSP responder is reachable from the server.
- The stapled response can be refreshed every few hours.
- If the responder fails, the server can continue serving with a cached stapled response until it expires.
CRLs as a fallback cover the cases where stapling isn't available. At enterprise scale — 50K to 250K certificates per organisation, with single-digit percentages revoked — CRLs fit in a few megabytes, can be fetched on a cadence, and can be cached.
The enterprise revocation model works because the infrastructure assumptions hold. Pull any of those assumptions and the model breaks.
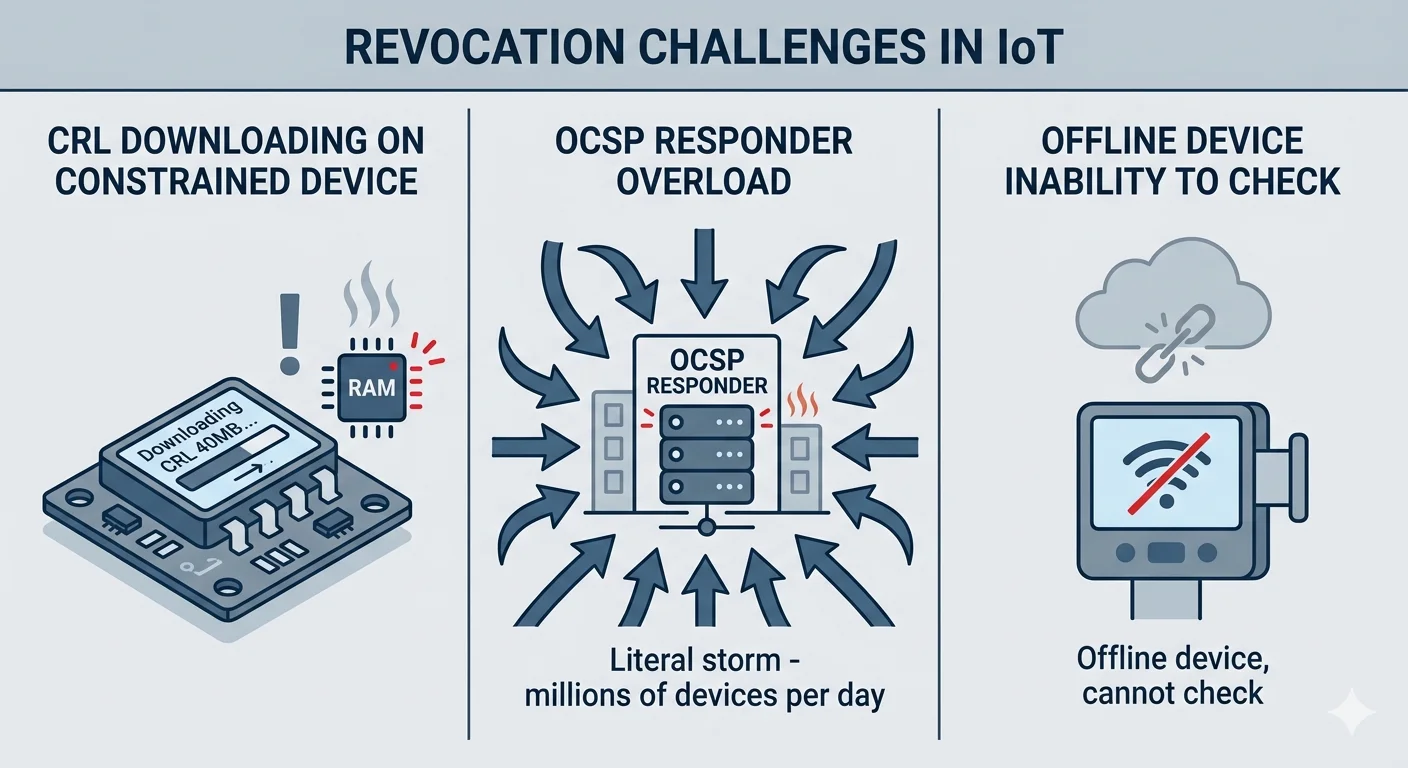
Why OCSP fails at device scale
OCSP at device scale fails in four distinct ways, and the failure modes compound.
Devices often have no path to the responder. A smart lock on a home WiFi network, behind consumer NAT, with intermittent cloud connectivity, cannot make an OCSP request every time it validates a certificate. An industrial sensor on an air-gapped OT network has no path to a public OCSP responder by design. The assumption that "the relying party can make an OCSP request" is the assumption that doesn't survive crossing into device territory.
OCSP responders become fleet-wide single points of failure. An OCSP responder serving a million-device fleet is a load concentration point. When it fails, every device attempting to verify a peer certificate fails. When it is DDoS'd, the fleet is effectively offline. The enterprise response — over-provision the responder — is expensive and doesn't scale to the tens of millions of devices that some Matter-adjacent ecosystems will reach.
Soft-fail is the default and it provides no guarantee. RFC 6960 permits relying parties to soft-fail on OCSP unreachability — accept the certificate rather than break the connection. Most relying party implementations soft-fail by default because hard-failing causes too many false-negative rejections. A soft-fail relying party does not provide revocation; it provides revocation when the responder happens to be reachable. That is not a security property.
OCSP nonce handling is broken in most implementations. The nonce mechanism that prevents replay is optional, often not implemented in responders, and not always checked in clients. A cached OCSP response can be replayed against a relying party that doesn't verify freshness. This matters less at enterprise scale where the caching window is short; at device scale it widens the window of a revoked credential continuing to be accepted.
OCSP stapling solves the first three problems for servers. Devices are clients, not servers, and OCSP stapling does not solve the client-side verification problem.
Why CRLs fail at device scale
CRLs have a simpler failure mode: size.
A CRL for a million-device fleet with even 1% cumulative revocation reaches 50MB uncompressed in typical certificate serial number encoding. Compressed, it may be 15–25MB. A constrained device with 2MB of flash cannot store it. A device on a cellular connection cannot download it on every boot. A fleet-wide CRL push is a distribution problem closer to content delivery than PKI.
CRLite and related bloom-filter-based compression schemes are research responses to this problem at web scale. Mozilla's CRLite reduces full web PKI revocation state to a few megabytes of compressed bloom filters. For a large device fleet with its own private CA, similar compression is viable but requires custom infrastructure.
The practical CRL use cases at device scale:
- Small device fleets (under 100K devices): CRLs remain tractable.
- Infrequent, targeted revocation: a few dozen revoked certificates don't create size problems.
- CA-level emergency revocation: when the CA itself is compromised, the CRL lists a handful of CA certificates, and the device needs to learn to distrust them.
CRLs do not disappear from the unified PKI. They stop being the primary revocation mechanism for device fleets.
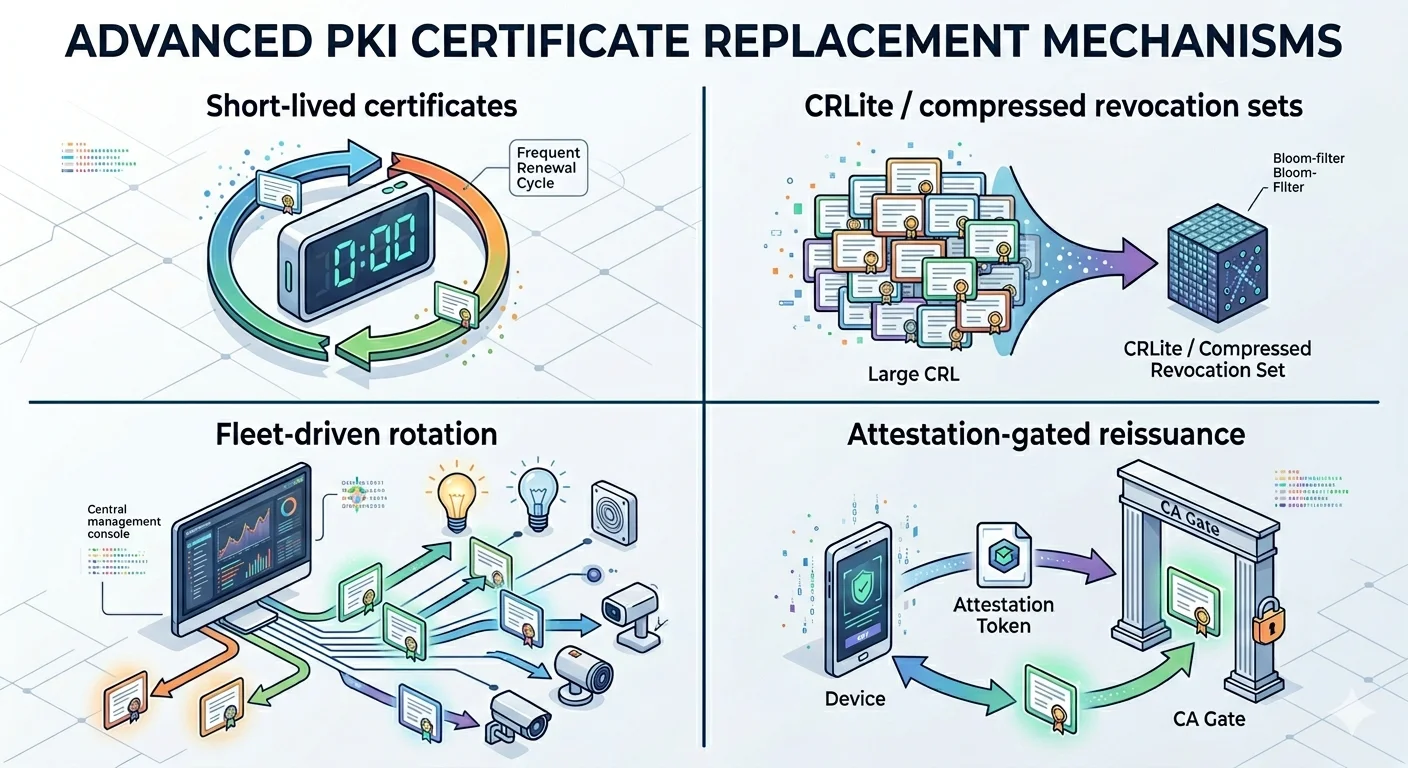
The three working alternatives
Three mechanisms actually work at device scale. Each has clear trade-offs. The production answer is usually a combination.
Alternative 1: Short-lived LDevIDs as implicit revocation
If the certificate's validity is short enough, revocation becomes unnecessary. The certificate expires, the device re-enrolls if authorised, the compromised certificate becomes useless without an explicit revocation event. This is the IEEE 802.1AR LDevID model applied with short lifetimes.
How short is short enough? The answer depends on incident response tolerance. If a compromised LDevID must be invalidated within 24 hours, LDevID lifetime of 24 hours is sufficient. If 7 days is acceptable, 7-day lifetimes work. Most production deployments settle at 24 hours to 7 days for LDevIDs issued to always-online devices, longer for intermittent-connection devices where shorter lifetimes cause re-enrollment storms.
What this requires:
- The CA must be available for re-enrollment at the required cadence.
- The device must have connectivity within the renewal window.
- The enrollment protocol — typically EST — must support re-enrollment using the current certificate as authentication.
- The IDevID underneath must remain long-lived so devices that miss renewal windows can re-bootstrap.
Where this breaks: devices that are offline for longer than the LDevID lifetime. If a device is in storage for six months and the LDevID lifetime is 30 days, the device needs a bootstrap path back to enrollment. The IDevID provides this, but only if the device hardware and firmware support using the IDevID for re-authentication after LDevID expiry.
Alternative 2: Gateway-enforced revocation
The device itself does not check revocation. A gateway — either at the edge of the device's network or at the cloud ingress — checks on the device's behalf. The device trusts the gateway; the gateway enforces the revocation policy.
This is the operational model for most large-scale IoT deployments. The device authenticates to the gateway with its certificate; the gateway verifies the certificate against a current revocation state (fetched, updated, managed as infrastructure); if the certificate is revoked, the gateway drops the connection.
How it works in practice:
- The gateway maintains current revocation state — CRL, OCSP cache, custom revocation service — refreshed on a cadence it controls.
- Device-to-device communication, if any, goes through the gateway or through a gateway-mediated discovery mechanism.
- The gateway is the enforcement point; the device is simplified.
Where this breaks: device-to-device direct communication. Matter devices authenticate to each other directly within a fabric; the Matter commissioning authority and fabric admin provide revocation signals, but there is no central gateway. Matter handles this through fabric-level trust and limited operational certificate lifetimes — an architectural decision made explicitly to avoid needing scalable revocation.
Alternative 3: RFC 9773 ARI renewal pressure
RFC 9773 ACME Renewal Information, published in 2025, defines a mechanism for the CA to signal renewal windows to ACME clients, including the ability to request early renewal. A CA that wants to retire a certificate — for key material concerns, algorithm deprecation, or policy change — can signal clients to renew earlier than the certificate's notAfter date.
ARI is not revocation. It is preemption: if clients renew in response to the signal, the original certificate becomes obsolete before it becomes a revocation problem. For well-automated estates, ARI reduces revocation event frequency significantly.
What ARI provides:
- Graceful rotation pressure before explicit revocation.
- Audit signal that the CA flagged the certificate for early renewal.
- Client-side renewal decisions that distribute load rather than concentrating at CRL/OCSP fetch time.
What ARI does not provide:
- Guaranteed revocation for clients that don't check ARI.
- Coverage for EST, SCEP, or CMPv2 clients — ARI is ACME-specific.
- Real-time revocation for known-compromised certificates.
ARI is a complement to, not replacement for, revocation. In the unified PKI, ARI covers the ACME-enrolled estate — typically the enterprise side and some IoT gateway layers — while short-lived LDevIDs and gateway enforcement cover the device side.
Adaptive revocation patterns
"Adaptive cert revocation" appears as a query in our search data at position 6. The term isn't formally defined across the industry, but the practitioner usage consistently refers to hybrid models that adjust revocation strategy based on certificate class and deployment context.
A working adaptive revocation model:
- Enterprise TLS: OCSP stapling + ARI for renewal pressure + CRL fallback. Standard web PKI.
- Workload identity: short-lived SVIDs, no revocation mechanism needed at the SVID layer, trust domain governs.
- Device LDevID (connected): short lifetime (24h–7d) + gateway revocation check + ARI if ACME-enrolled.
- Device LDevID (intermittent): longer lifetime (30d–1y) + gateway revocation check + IDevID-based re-bootstrap on anomaly.
- Device IDevID / DAC: no operational revocation; compromise is a CA-level event handled by fleet-wide IDevID replacement.
- IEEE 2030.5 / smart grid endpoints: per IEEE 2030.5-2023 specifications, revocation integrates with the utility's DERMS infrastructure and uses out-of-band revocation signals.
The adaptive model matches the revocation mechanism to the certificate class rather than forcing one mechanism across all.
Device retirement as a revocation event
When a device reaches end of life, the certificate issued to it should not continue to authenticate. This is the retirement revocation case, and it is distinct from compromise revocation.
The operational question: when the device is physically decommissioned, what happens to its certificate?
The answers range by architecture:
- Short-lived LDevID model: the LDevID expires. The IDevID is no longer presented anywhere. No explicit action required.
- Long-lived LDevID model: the device must be actively revoked. Without explicit revocation, the certificate remains technically valid until its notAfter date.
- Matter retirement: the device is removed from the Matter fabric, the NOC is effectively orphaned, and the DAC remains valid but unused. Matter has no central revocation mechanism for DACs at device retirement.
- Industrial device retirement: depends on the PKI and the industrial protocol. Without specific end-of-life revocation process, retired device certificates often remain valid.
The unified PKI must have a retirement revocation process distinct from compromise revocation, and the process must execute at device retirement time — not years later during an audit that notices the orphaned certificates.
The unsolved cases
Being honest about what doesn't work:
Revocation of long-lived IDevIDs at scale. If a batch of IDevIDs issued by a manufacturer is compromised — the 2018 Intel ME key exposure is an instructive case — the working response is firmware update to accept a new IDevID, not certificate revocation in the traditional sense. This assumes the devices support such updates. Many don't.
Matter DAC compromise response. If a Matter PAA or PAI is compromised, the CSA revokes the compromised CA, and Matter ecosystems update their trust stores. Individual DACs under the compromised CA are invalidated by CA revocation, not by DAC-level revocation. This is a fleet-wide event handled through ecosystem update.
Air-gapped OT networks. Devices with no connectivity to any revocation infrastructure cannot check revocation. The compensating control is physical access control, segmentation, and accepting that revocation is an operational procedure executed manually rather than a cryptographic mechanism.
Devices operating past manufacturer end-of-life. A device whose manufacturer has ceased to exist continues to present its certificate. Revocation mechanisms that depend on the manufacturer's CA or responder cease to function. This is a 10+ year problem that will manifest in the 2030s as the first wave of Matter devices age past manufacturer support.
What this means for platform selection
Revocation questions for unified PKI platform evaluation:
- Does the platform support per-profile revocation mechanism selection — OCSP, CRL, ARI, gateway-enforced — or does it apply one mechanism uniformly?
- Does CRL generation support large fleets without linear size growth — incremental CRLs, partitioned CRLs, or bloom-filter compression?
- Does the platform expose RFC 9773 ARI for ACME-enrolled certificates?
- Is there a retirement revocation workflow distinct from compromise revocation, with explicit device decommissioning integration?
- How does the platform handle IEEE 2030.5, Matter, and other ecosystem-specific revocation semantics?
- What is the audit trail for revocation events across all mechanisms — not just OCSP responder logs?
A platform that answers one mechanism for all certificates — "we use OCSP" — is designed for enterprise, not the mixed estate. A platform that answers "we generate per-device CRLs" is designed for small fleets. The working platform answers "profile-dependent, documented, with audit coverage across all mechanisms."