![Dan Cvrcek [Tsvrcheck]](/blog/assets/images/bio-photo.jpg)


localhost Is Not an Identity: Certificate Anti-Patterns in Multi-Cluster Kubernetes
 Secure centralized hierarchy with identity management
Secure centralized hierarchy with identity management
Most Kubernetes clusters ship with the same two certificate shortcuts baked in from day one: loopback addresses (localhost, 127.0.0.1) stuffed into certificate SANs, and a fresh self-signed CA spun up for every cluster. Both feel harmless. Neither is.
But here’s what most security write-ups won’t tell you: these aren’t mistakes. They’re the default path. cert-manager’s quickstart guide, the top-voted Helm chart configurations, the StackOverflow answers your platform team copied last quarter — they all optimise for “working TLS in five minutes,” not “secure PKI at scale.” The ecosystem has trained an entire generation of Kubernetes operators to treat certificate issuance as a bootstrapping detail rather than an architectural decision.
These patterns work fine on a laptop. In production — especially multi-tenant, multi-cluster, or regulated environments — they silently dismantle the zero-trust model that justified your Kubernetes investment in the first place.
The localhost Certificate Problem
When you issue a TLS certificate with localhost as its identity, you’ve created a credential that says “I am… any local service.” That’s not identity. That’s a skeleton key for anything sharing the same network namespace.
 Localhost is not identity
Localhost is not identity
What actually goes wrong
Impersonation becomes trivial. Any pod with access to that certificate Secret can present it as proof of identity on loopback traffic. In clusters using hostNetwork: true — common for ingress controllers, CNI plugins, and monitoring agents — a leaked TLS Secret enables man-in-the-middle attacks without ever touching the network boundary.
Lateral movement gets easier. Because localhost isn’t namespaced or workload-specific, the same cert works in any namespace. A compromised dev environment can leak a localhost cert sideways into production namespaces, and it will look perfectly valid to anything trusting the issuing CA.
Audit trails go dark. Unlike a certificate for payments.prod.svc.cluster.local, a localhost cert tells you nothing about which workload used it, when, or why. Forensic analysis after a breach hits a dead end. Compliance scanners — Trivy, kube-bench, Aqua, Prisma — flag these as high-severity findings for good reason.
Standards say no. RFC 5280 discourages localhost in production certificates. PCI-DSS 4.0, SOC 2, and NIST 800-53 all require unique, verifiable identities. A localhost cert fails every one of those tests.
None of this is news to security teams. The uncomfortable question is why it keeps happening — and the answer is that fixing it requires someone to own the problem across team boundaries. More on that below.
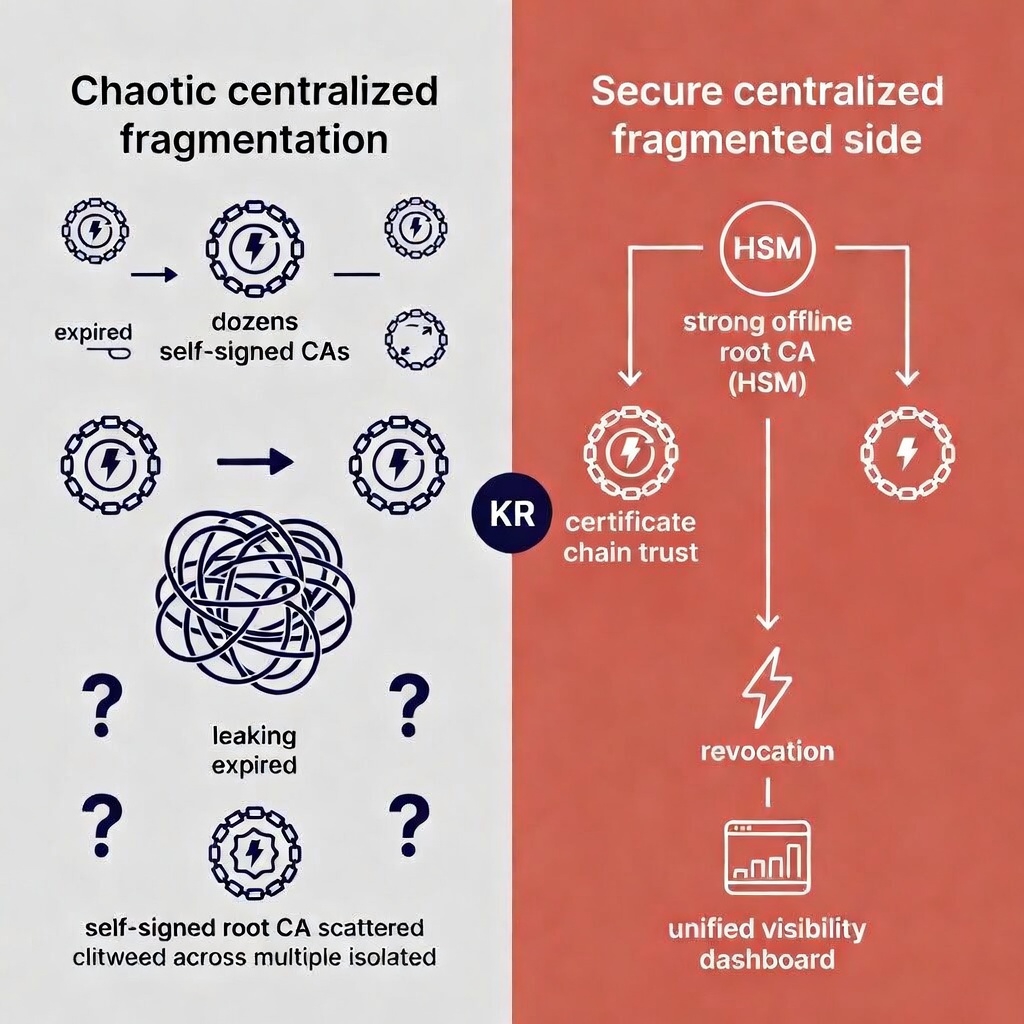
The Throwaway CA Problem
Spinning up a new self-signed CA for every cluster is the default “quick start” in cert-manager, smallstep, cfssl, and Vault PKI tutorials. It feels like isolation. It’s actually fragmentation.
The industry frames per-cluster CAs as a security boundary. In practice, they’re an organisational boundary — each cluster’s CA reflects whichever team provisioned it, with whatever defaults they happened to use that week.
What actually goes wrong
Revocation doesn’t exist. Each cluster’s CA has its own private key with no central revocation mechanism. If one cluster’s CA key leaks — via an etcd backup, a misconfigured S3 bucket, or an insider — there’s no efficient way to revoke trust across 50, 100, or 500 clusters. Most ad-hoc CAs don’t even have a CRL or OCSP endpoint configured. The industry talks about “crypto agility” and rapid rotation, but most fleet operators can’t even enumerate their active CAs — let alone rotate them under pressure.
Isolation is an illusion. The moment any root CA cert gets copied into a shared ConfigMap, a secret store, or another cluster’s trust bundle — and it always does — the walls collapse. A certificate issued in Cluster A becomes valid in Cluster B. This is the most common cross-cluster exploitation vector in certificate-related incidents. The per-cluster CA was supposed to contain blast radius. Instead, it just distributed the attack surface.
Discovery becomes impossible. Without a central PKI hierarchy, nobody can answer: “How many active CAs do we have? Which ones use 4096-bit keys? Which are still on SHA-1? Which expired last week?” At fleet scale, this is not a theoretical risk — it’s an operational blind spot that grows with every new cluster.
Bootstrap is the weakest moment. Ad-hoc CAs are typically generated during cluster provisioning, often with weak entropy, default passwords, and no HSM backing. Attackers targeting GitOps or Terraform pipelines can inject malicious root CAs before anyone is watching.
Why the Combination Is Toxic for Enterprises
Put both patterns together and the attack chain writes itself:
- A developer in Cluster A requests a localhost cert from the local throwaway CA.
- The CA root — or the cert itself — leaks or gets synced to Cluster B.
- The cert now works for local man-in-the-middle attacks in Cluster B, because both the loopback name and the signing CA are trusted there.
- No workload identity exists to block the impersonation.
- Logs show “valid” certificates from “trusted” CAs. Detection is nearly impossible.
The numbers make it clear this isn’t a niche problem. Red Hat’s 2024 State of Kubernetes Security report found that 89% of organisations experienced at least one container or Kubernetes security incident in the prior 12 months — with 40% detecting misconfigurations in their environments. Nearly half (46%) lost revenue or customers as a direct result. Separately, Venafi’s 2023 cloud-native security survey reported that 59% of organisations experienced security incidents in their Kubernetes or container environments, with certificate misconfigurations among the top causes — and 30% of those incidents led to a data breach or network compromise. Earlier Red Hat data showed misconfigurations accounting for 59% of all Kubernetes security incidents.
The reason it persists isn’t that teams are careless. It’s that “set up TLS” and “design a PKI architecture” are treated as the same task — and they’re not even close.
What To Do Instead (And Why Each Option Has Limits)
There is a general assumption that better tooling fixes what is fundamentally an ownership gap. Every option below works. None of them works on autopilot.
Still, you need to present a more secure options that is at least as easy as the use of the default configurations.
1. Replace localhost SANs with proper service identities
Every certificate should identify a specific workload. At minimum, use fully qualified internal DNS names:
myservice.mynamespace.svc.cluster.local
This gives you traceable identity per namespace and service — enough for audit trails, policy enforcement, and meaningful mTLS.
The catch: This requires every team to request the right SANs, which means someone has to define and enforce a naming convention. Without that governance layer, you’ll trade localhost certs for a different flavour of inconsistency.
2. Enforce issuance policy at the platform level
Deploy approver-policy with CEL rules that reject loopback SANs outright. Combine this with namespace labels so teams get self-service issuance within guardrails — not a free-for-all.
Example policy: deny any CertificateRequest where SANs contain localhost, 127.0.0.1, ::1, or unqualified short names. This is a ten-minute change that eliminates an entire class of risk.
The catch: Policy without ownership decays. Someone needs to maintain the rules, handle exceptions, and update them as the cluster topology evolves. A policy file committed once and never reviewed is just documentation with enforcement powers.
3. Adopt workload identity (SPIFFE)
SPIFFE and its Kubernetes implementation (csi-driver-spiffe) assign cryptographic identities to workloads automatically — no manual cert requests, no localhost hacks. The identity format (spiffe://cluster.local/ns/payments/sa/api-server) is purpose-built for zero-trust service mesh environments. Istio and Linkerd already support it natively.
The catch: SPIFFE solves the identity problem cleanly, but it doesn’t fix CA fragmentation on its own. If each cluster still runs its own SPIRE server with its own root of trust, you’ve replaced ad-hoc CAs with ad-hoc SPIFFE roots — a more elegant version of the same structural problem.
4. Centralise your PKI hierarchy
Replace per-cluster throwaway CAs with a proper hierarchy: a single offline root CA (ideally HSM-backed), with intermediate CAs issued per cluster or per environment. This gives you one place to revoke, fleet-wide visibility, and consistent key standards enforced from the top down.
Tools like Vault PKI, AWS Private CA, or Google Cloud CAS can serve as the central authority. cert-manager integrates with all of them as an external Issuer.
The catch: This is where most organisations stall. Centralising PKI is treated as a migration project — a one-time effort to “fix” the architecture. In reality, it’s an ongoing operational commitment: key ceremonies, rotation schedules, cross-cluster trust bundle distribution, incident response procedures. Teams that centralise the hierarchy but don’t staff the operations end up with a single point of failure instead of a distributed mess.
5. Automate discovery and lifecycle management
You cannot secure what you cannot see. Implement certificate discovery across your fleet so you can answer the basic questions: what exists, who issued it, when does it expire, and does it comply with policy?
This is the operational layer most teams skip — and it’s where the real pattern becomes visible. Issuance, renewal, rotation, revocation, and compliance reporting aren’t five separate problems. They’re one lifecycle that needs a single owner.
The Actual Problem Nobody Wants to Name
Every solution above is technically sound. The reason organisations cycle through them without resolving the underlying risk is that (partially) automated certificates fall into a no-man’s-land between security, platform engineering, and application teams.
Security sets the policy but doesn’t operate the clusters. Platform engineering runs cert-manager but doesn’t own the compliance requirements. Application teams request the certs but don’t think about PKI architecture. The result is that everyone assumes someone else is responsible — and the defaults win by inertia.
The organisations that actually fix this don’t start with a tool migration. They start by answering one question: who owns the certificate lifecycle as a platform concern? Once that’s settled, the technical choices that fit particular circumstance of the company to get everyone behind agreed changes — SPIFFE, centralised CA, policy enforcement — follow naturally. Without it, every improvement is a point fix in a system that nobody is steering.
Why a cross-cluster platform layer changes the dynamic
The common objection is: “We can’t assign ownership until we understand the scope.” Fair — but that’s circular.
A platform that connects certificate data across clusters breaks this deadlock. Not by replacing cert-manager or your CA hierarchy — those remain the operational layer — but by creating a single view of what actually exists: every CA, every certificate, every issuance policy, every expiry, every violation, across every cluster.
This surely does sound like a monitoring pitch but here we go. The shift is more fundamental than dashboards and alerts. When one platform surfaces that Cluster A has 14 active CAs (three of them expired), Cluster B is issuing localhost certs at a rate of 200 per week, and Cluster C’s self-signed root leaked into the trust bundle of six other clusters last Tuesday — someone has to respond. The ownership question stops being philosophical and becomes operational.
That’s the real function of a cross-cluster certificate platform: it doesn’t solve the ownership problem — it makes the ownership vacuum impossible to ignore. Discovery forces triage. Triage forces accountability. Accountability forces changes, smart tooling gives engineers means to make changes happen.